Databricks Vector Search is now available in public preview, offering a serverless vector database for efficient similarity search. Powered by Databricks’ serverless compute infrastructure, Vector Search integrates with Delta tables, Unity Catalog, and Model Serving for seamless management and access. This article embarks on a simple, step-by-step exploration of this new feature through the process of creating a vector search endpoint, establishing an external OpenAI model serving endpoint, and building a Delta Sync Index with managed embeddings. We’ll conclude our little experiment by conducting a similarity search.
Data preparation
First off, to comply with limits in model input size, we split a PDF file that we previously uploaded to a Databricks Volume.
%pip install Pdfplumber langchain
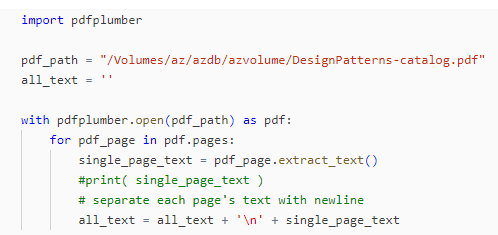

Now that we have our chunks of text, we’ll store them in a source Delta table with Change Data Feed enabled.
- We’re using an Identity column.
- The column ‘embedding‘ is not needed since Databricks is taking care of generating those.
- The ‘text’ column - which is holding the content of the text chunks – is the embeddings source column.

We’ll use a pandas UDF for the SQL insert. This UDF will simply return the text sections.


We can check the content of the table:

Vector Search
Now that we have our data, we can start thinking about creating a vector search index. We have a couple of options:
- We could go for a Direct Vector Access Index to manage embedding vectors and index updates ourselves.
- We could let Databricks manage those for us. A Delta Sync Index will automatically sync with the source Delta table when that table gets updates. As for managing embeddings, we can still choose to do it ourselves, or let Databricks do it for us. In this article, we’ll go for the latter.

The plan is to:
- Create the vector search endpoint that will hold access to the index(es).
- Create the embedding model endpoint, so that embeddings are automatically generated.
- Create a Delta Sync index for automatic sync-ing with the source Delta table.
- Perform a similarity search using the vector search index.
Under the hood, Databricks Vector Search uses the HNSW index type and cosine similarity search, which were both covered in a previous article.
Vector Search Endpoint
Search endpoints are used to create and access indices. They will automatically scale with the number of vectors in the indices and the volume of concurrent requests.
%pip install databricks-vectorsearch


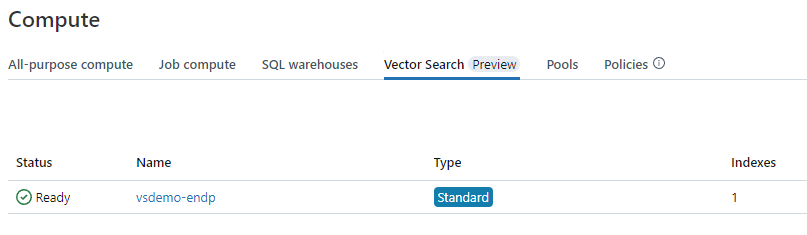
We need to wait for the endpoint to transition from the provisioning state to the ready, ‘online’ state. We could do that in code, using a loop and checking the status…or simply wait a bit. Once online, the search endpoint is visible through the UI, in the Compute / Vector Search section.
Model Serving Endpoint
We’re not quite done with endpoints. In order to create an auto-sync vector search index, we also need a model serving endpoint, since we plan for the embedding vectors to be automatically computed for us by Databricks.
We can create the model serving endpoint either in code, or using the UI. We’ll do a bit of both, i.e. create the endpoint in code and test it using the UI, before proceeding to the index creation.
%pip install mlflow[genai]>=2.9.0

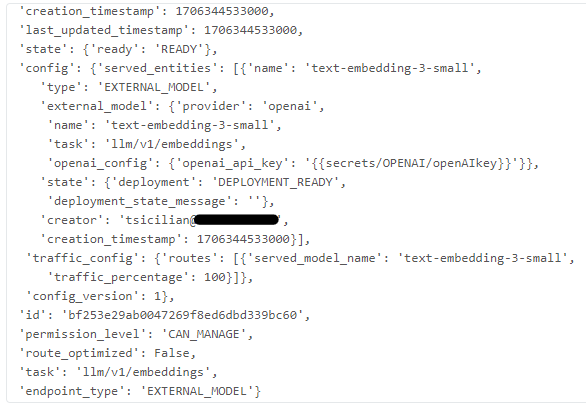
We used MLflow to create an external, OpenAI text embedding model endpoint. Note that the OpenAI API key was previously saved in Databricks secrets. We also need credits in order to call the OpenAI platform API from our application, otherwise we’ll get a ‘quota exceeded‘ error…
We could have used any other supported external model, but the general principles are quite similar.
The model is now listed in the UI, under the Machine Learning / Serving section. Let’s run a quick test:

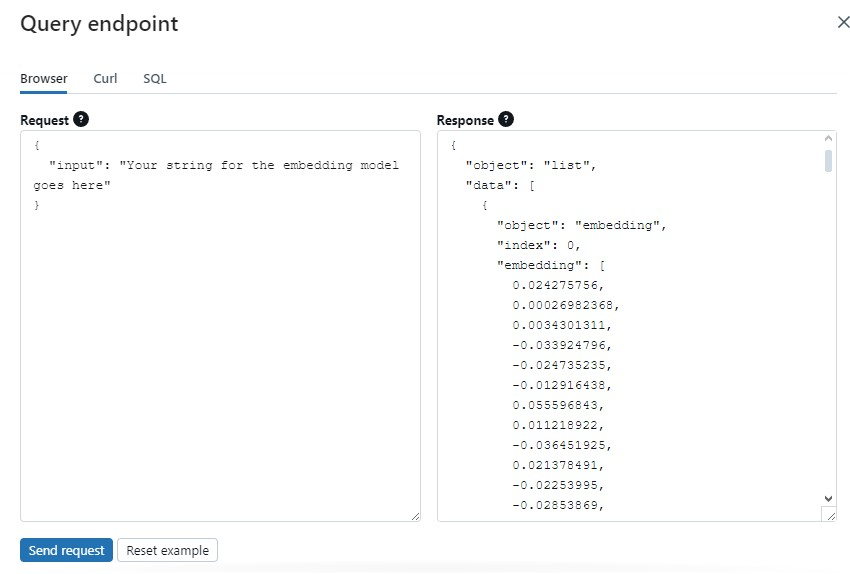
Delta Sync Index
Now that we created both vector search and model serving endpoints, we can create our index:
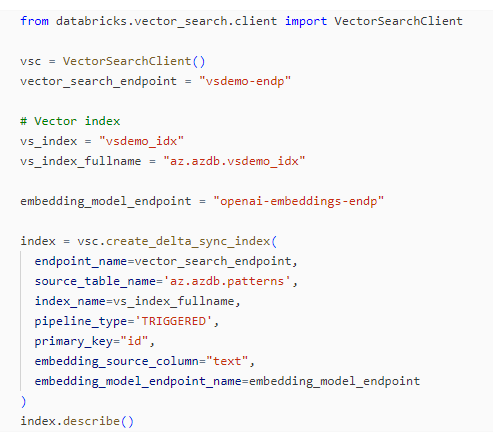

Note that we created a triggered Delta Sync index. The other option would be ‘continuous‘, which is a (more costly) sync streaming pipeline.
Here too, we need to wait for the index to go from the ‘provisioning’ state to ‘online’, which can be monitored through the Catalog Explorer UI:

In the Compute / Vector Search tab, the search endpoint is now listed as having one index. We can have multiple indices under a single search endpoint.
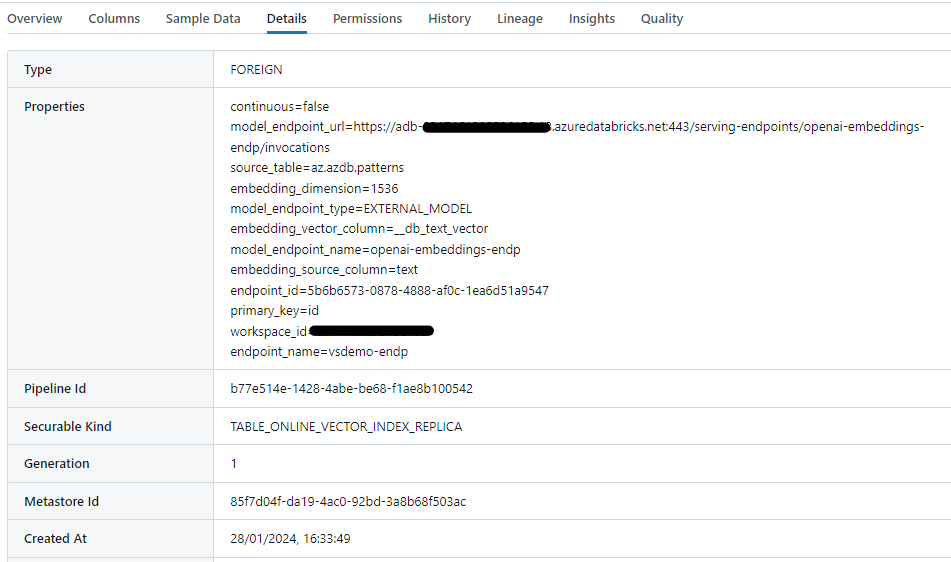
Note that the created index is listed as a table (not a Delta table), with Details information and schema. However, a ‘sample Data’ view on indices is not supported at this point.

Clicking on ‘Details’ tab:
Clicking on the ‘Sample Data’ tab:

If we intend to view the data with code…

We get the error message ‘TABLE_ONLINE_VECTOR_INDEX_REPLICA of a securable kind does not support Lakehouse Federation‘, possibly having to do with the source being hosted on the Databricks serverless side (where the underlying vector database would be located). It would indeed be considered an external source as the Details view above lists the table as FOREIGN. In addition, a ‘securable kind‘ apparently does not allow access through the client Lakehouse federation capabilities… at least for now. Anyway, in the absence of additional information, let’s stop making assumptions.

Similarity Search
Finally, we can run a search with our newly created index:


The last results bits give an indication of retrieval speed. The ann_time field refers to the Approximate Nearest Neighbor (ANN) algorithm typically used to speed up vector search.
Closing thoughts
Databricks Vector Search shares the same use cases as most vector databases: Retrieval Augmented Generation (RAG) systems, recommendation engines, image or video recognition, anomaly detection, and more. As a vector database, it is obviously designed to be scalable and low-latency.
As a Databricks service in particular, the search index can be sync-ed from a source Delta table with Change Data Feed enabled, so changes to the Delta table will automatically be reflected in the index. Additionally, since all of these resources are created under Unity Catalog’s governance umbrella, appropriate permissions can be set on the components involved.
Finally, be aware of the current limitations and restrictions on resource and data size. Other than that, consider putting vector search to the test.
